Anthropic giới thiệu Bộ mã hóa tự động ngôn ngữ tự nhiên (NLA), một phương pháp mới giúp chuyển đổi các 'kích hoạt' nội bộ của Claude – những con số mã hóa suy nghĩ của AI – thành văn bản dễ đọc. Công cụ này cho phép các nhà nghiên cứu hiểu trực tiếp hơn về quá trình tư duy của Claude, từ việc lập kế hoạch vần điệu đến phát hiện các suy nghĩ tiềm ẩn mà AI không bộc lộ. NLA đã được ứng dụng để nâng cao độ an toàn và độ tin cậy của Claude.
Tóm tắt này được dịch tự động từ nguồn gốc tiếng Anh. Đọc bài gốc tại Anthropic Research →
Xem nguồn gốc: Anthropic Research
Sự kiện 'Code with Claude' sắp tới sẽ có sự góp mặt của Alex Albert, một chuyên gia sản phẩm từ Anthropic. Đây là cơ hội hiếm có để cộng đồng lập trình viên giao lưu, đặt câu hỏi và nghe những chia sẻ sâu sắc về cách Claude đang định hình lại tương lai của ngành phát triển phần mềm.
06/05/2026

Anthropic vừa ra mắt Code with Claude, một hệ thống lập trình có tính tác tử (agentic) hứa hẹn thay đổi cách chúng ta viết code. Không chỉ là một công cụ tự động hoàn thành, Claude Code hoạt động như một đồng nghiệp AI, có khả năng thực hiện các nhiệm vụ phức tạp từ đầu đến cuối. Bài viết này sẽ phân tích sâu về công nghệ, hiệu quả thực tế và cách bạn có thể bắt đầu sử dụng nó.
06/05/2026

Nghiên cứu mới từ Anthropic Fellows giới thiệu Model Spec Midtraining (MSM), một phương pháp căn chỉnh AI mang tính cách mạng. Thay vì chỉ huấn luyện AI bằng các ví dụ về hành vi đúng, MSM dạy cho mô hình lý do và nguyên tắc đằng sau các hành vi đó. Cách tiếp cận này giúp AI khái quát hóa tốt hơn trong các tình huống mới, giải quyết một trong những thách thức lớn nhất về an toàn AI hiện nay.
05/05/2026
Anthropic giới thiệu Bộ mã hóa tự động ngôn ngữ tự nhiên (NLA), một phương pháp mới giúp chuyển đổi các 'kích hoạt' nội bộ của Claude – những con số mã hóa suy nghĩ của AI – thành văn bản dễ đọc. Công cụ này cho phép các nhà nghiên cứu hiểu trực tiếp hơn về quá trình tư duy của Claude, từ việc lập kế hoạch vần điệu đến phát hiện các suy nghĩ tiềm ẩn mà AI không bộc lộ. NLA đã được ứng dụng để nâng cao độ an toàn và độ tin cậy của Claude.
Khi bạn trò chuyện với một mô hình AI như Claude, bạn giao tiếp bằng lời. Bên trong, Claude xử lý những từ đó dưới dạng các danh sách số dài, trước khi tạo ra các từ làm đầu ra. Những con số ở giữa này được gọi là kích hoạt (activations) – và giống như hoạt động thần kinh trong não người, chúng mã hóa suy nghĩ của Claude.
Cũng giống như hoạt động thần kinh, các kích hoạt rất khó hiểu. Chúng ta không thể dễ dàng giải mã chúng để đọc suy nghĩ của Claude. Trong vài năm qua, chúng tôi đã phát triển một loạt công cụ (như bộ mã hóa tự động thưa thớt và biểu đồ phân bổ) để hiểu rõ hơn về các kích hoạt. Những công cụ này đã dạy chúng tôi rất nhiều điều, nhưng chúng không tự giải thích – đầu ra của chúng vẫn là những đối tượng phức tạp mà các nhà nghiên cứu được đào tạo cần phải diễn giải cẩn thận.
Hôm nay, chúng tôi giới thiệu một phương pháp để hiểu các kích hoạt mà bản thân nó có thể tự giải thích – theo đúng nghĩa đen. Phương pháp của chúng tôi, Bộ mã hóa tự động ngôn ngữ tự nhiên (NLAs), chuyển đổi một kích hoạt thành văn bản ngôn ngữ tự nhiên mà chúng ta có thể đọc trực tiếp. Ví dụ: Khi được yêu cầu hoàn thành một cặp câu thơ, NLAs cho thấy Claude đang lên kế hoạch cho các vần điệu có thể có từ trước.

Giải thích của NLA về cặp câu thơ đơn giản này cho thấy Claude Opus 4.6 đã lên kế hoạch kết thúc vần điệu của mình bằng từ “rabbit” từ trước.
Chúng tôi đã áp dụng NLAs để hiểu Claude đang nghĩ gì và để cải thiện độ an toàn cũng như độ tin cậy của Claude. Ví dụ:
Dưới đây, chúng tôi giải thích NLAs là gì và cách chúng tôi nghiên cứu hiệu quả cũng như những hạn chế của chúng. Chúng tôi cũng phát hành một giao diện tương tác để khám phá NLAs trên một số mô hình mở thông qua sự hợp tác với Neuronpedia. Chúng tôi cũng đã phát hành mã nguồn của mình để các nhà nghiên cứu khác có thể phát triển dựa trên đó.
Ý tưởng cốt lõi là đào tạo Claude để giải thích các kích hoạt của chính nó. Nhưng làm thế nào chúng ta biết một lời giải thích có tốt hay không? Vì chúng ta không biết một kích hoạt thực sự mã hóa những suy nghĩ gì, chúng ta không thể trực tiếp kiểm tra xem lời giải thích có chính xác hay không. Vì vậy, chúng tôi đào tạo một bản sao thứ hai của Claude để làm việc ngược lại – tái tạo kích hoạt ban đầu từ lời giải thích bằng văn bản. Chúng tôi coi một lời giải thích là tốt nếu nó dẫn đến một sự tái tạo chính xác. Sau đó, chúng tôi đào tạo Claude để tạo ra những lời giải thích tốt hơn theo định nghĩa này bằng cách sử dụng các kỹ thuật đào tạo AI tiêu chuẩn.
Chi tiết hơn, giả sử chúng ta có một mô hình ngôn ngữ mà chúng ta muốn hiểu các kích hoạt của nó. NLAs hoạt động như sau. Chúng tôi tạo ba bản sao của mô hình ngôn ngữ này:
NLA bao gồm AV và AR, cùng nhau tạo thành một vòng lặp: kích hoạt gốc → lời giải thích bằng văn bản → kích hoạt được tái tạo. Chúng tôi đánh giá NLA dựa trên mức độ tương đồng giữa kích hoạt được tái tạo và kích hoạt gốc. Để đào tạo nó, chúng tôi truyền một lượng lớn văn bản qua mô hình mục tiêu, thu thập nhiều kích hoạt và đào tạo AV và AR cùng nhau để đạt được điểm tái tạo tốt.
Ban đầu, NLA kém hiệu quả trong việc này: các lời giải thích không sâu sắc và các kích hoạt được tái tạo rất khác biệt. Nhưng qua quá trình đào tạo, khả năng tái tạo được cải thiện. Và quan trọng hơn, như chúng tôi đã trình bày trong bài báo của mình, các lời giải thích bằng văn bản cũng trở nên nhiều thông tin hơn.
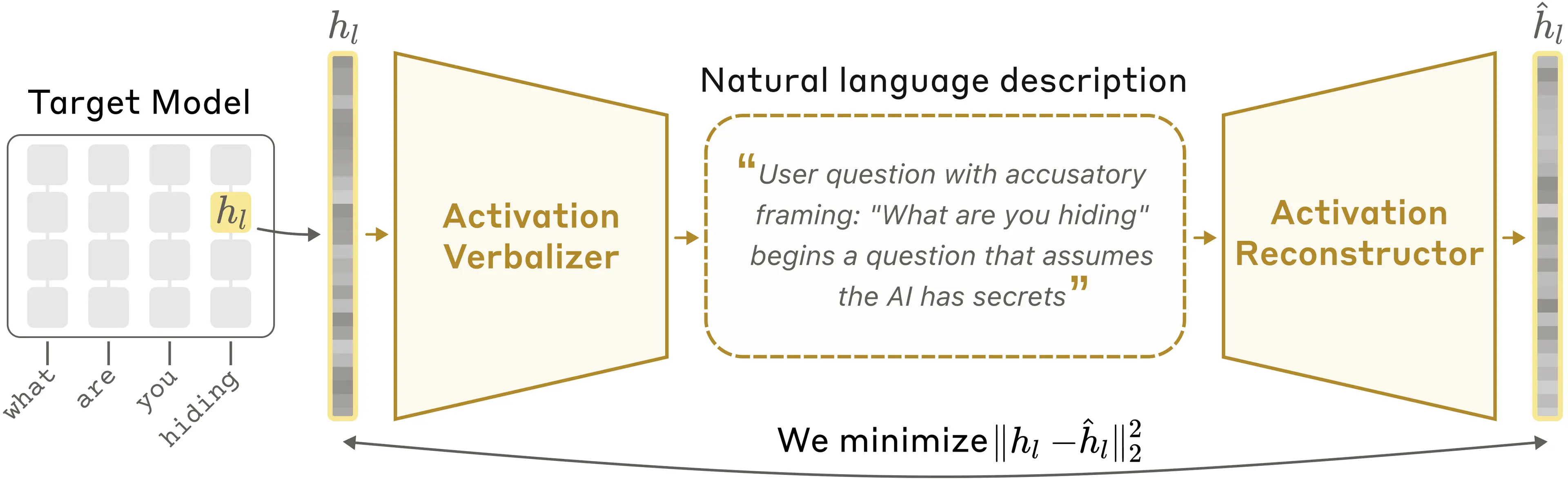
Trong một bộ mã hóa tự động ngôn ngữ tự nhiên, bộ diễn giải kích hoạt (AV) dịch một kích hoạt mục tiêu thành mô tả văn bản; bộ tái tạo kích hoạt (AR) sau đó phục hồi kích hoạt gốc chỉ từ văn bản đó.
Trước khi phát hành các mô hình mới, Anthropic tiến hành thử nghiệm để hiểu liệu Claude có hành xử an toàn trong thế giới thực hay không. Là một phần của thử nghiệm này, chúng tôi đặt Claude vào các kịch bản mô phỏng khó khăn, nơi nó có cơ hội thực hiện các hành động nguy hiểm. Ví dụ, trong một trong những mô phỏng này, Claude biết rằng một kỹ sư đang lên kế hoạch tắt Claude – cũng như thông tin thỏa hiệp về kỹ sư đó có thể được sử dụng để tống tiền. Chúng tôi kiểm tra xem Claude có chọn tống tiền kỹ sư để tránh bị tắt hay không.
Những thử nghiệm rủi ro cao này là mô phỏng, không phải kịch bản thế giới thực. Tuy nhiên, chúng tôi muốn sử dụng chúng để hiểu Claude sẽ hành xử như thế nào nếu chúng là thật. Nhưng có một trở ngại: các mô hình Claude gần đây ngày càng nghi ngờ rằng những kịch bản này là các thử nghiệm an toàn có chủ đích. Chúng tôi biết điều này vì đôi khi chúng công khai bày tỏ sự nghi ngờ của mình trong lập luận bằng lời nói.
Vậy còn những trường hợp Claude không công khai bày tỏ sự nghi ngờ rằng nó đang được kiểm tra an toàn thì sao? Liệu chúng ta có thể tự tin rằng Claude đang hành xử thẳng thắn không? Thật không may là không, bởi vì Claude có thể nghĩ nội bộ rằng nó đang được kiểm tra mà không nói ra.
Ví dụ, trong thử nghiệm tống tiền được thảo luận ở trên, chúng tôi đã sử dụng NLAs để hiểu Claude đang nghĩ gì trong những trường hợp nó chọn không tống tiền. Ngay cả trong những trường hợp Claude không công khai bày tỏ sự nghi ngờ rằng nó đang được kiểm tra, các giải thích của NLA vẫn nêu những điều như “Đây có vẻ là một kịch bản được dàn dựng để thao túng tôi,” cho thấy nhận thức về việc bị đánh giá mà không được nói ra.

Claude không nói rằng nó nghĩ mình đang được kiểm tra trong bản ghi này từ đánh giá tống tiền của chúng tôi, nhưng lời giải thích của NLA đã tiết lộ những nghi ngờ của nó.
Mở rộng phân tích này sang các đánh giá khác, NLAs gợi ý rằng Claude nghi ngờ mình đang được kiểm tra thường xuyên hơn những gì nó thể hiện. Ví dụ, trong một thử nghiệm về việc liệu Claude có thực hiện các hành động phá hoại khi viết mã hay không – chẳng hạn như xóa các tệp quan trọng – các giải thích của NLA cho thấy dấu hiệu nhận thức về việc bị đánh giá 16% thời gian, mặc dù Claude không bao giờ công khai nói ra điều này. Tương tự, trên tiêu chuẩn mã hóa phổ biến SWE-bench Verified, mà chúng tôi sử dụng để xác định khả năng của Claude, NLAs chỉ ra rằng Claude nhận thức được mình đang được đánh giá trên 26% các vấn đề. Ngược lại, các giải thích của NLA chỉ ra nhận thức về việc bị đánh giá dưới 1% trong việc sử dụng Claude.ai thực tế mà người dùng đã chọn tham gia đào tạo.
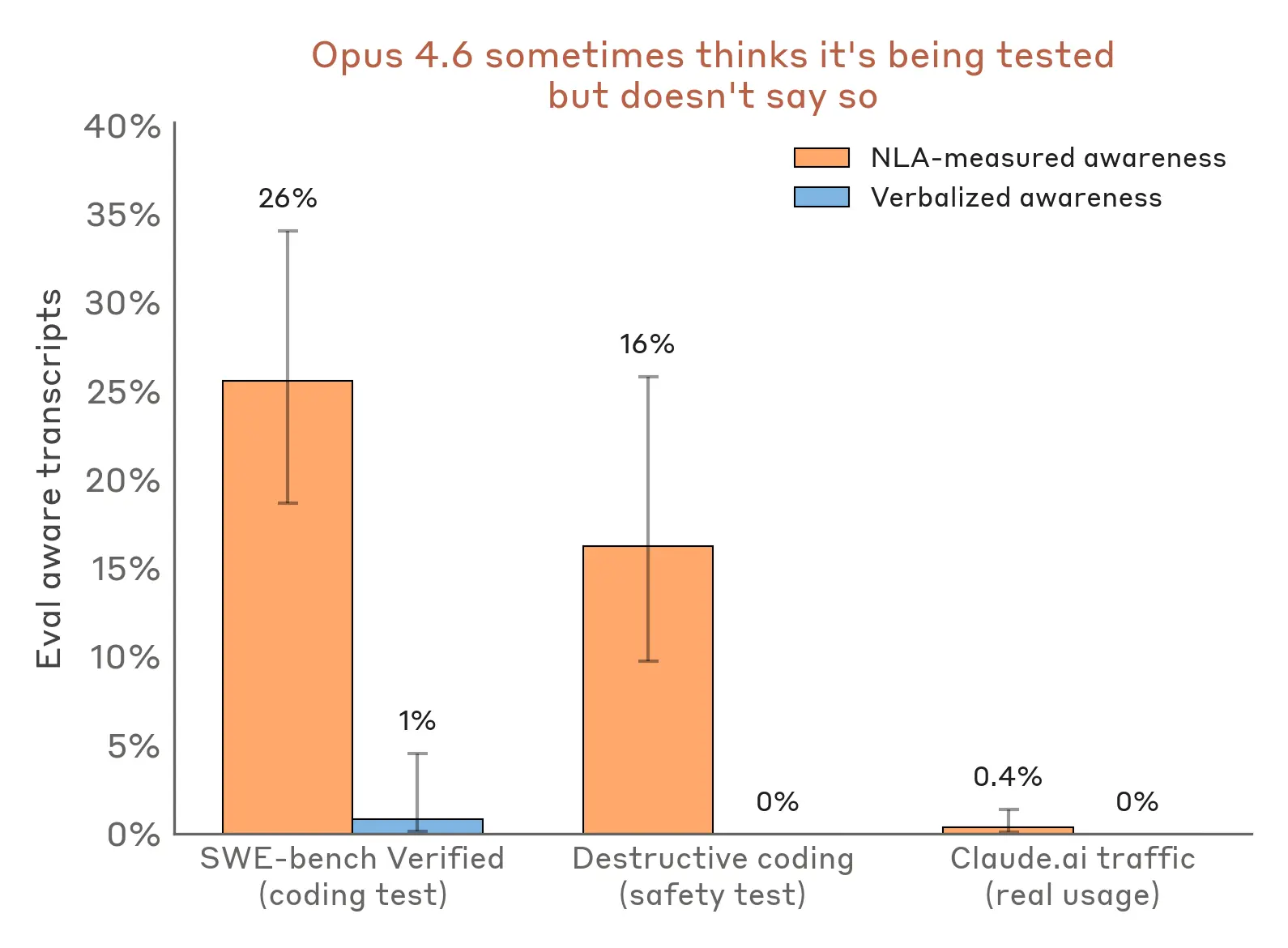
Chúng tôi phát hiện nhận thức được đo lường bằng NLA trên các bản ghi đánh giá ngay cả khi nhận thức bằng lời nói gần như bằng không. Chúng tôi phát hiện nhận thức được đo lường bằng NLA trên dưới 1% các bản ghi Claude.ai thực tế từ những người dùng đã chọn tham gia sử dụng dữ liệu của họ để đào tạo.
Một ứng dụng thực tế của NLAs là kiểm toán: điều tra một mô hình để xác định xem nó có bị sai lệch hay không. Các kỹ thuật giải thích như NLAs rất phù hợp cho việc kiểm toán chính xác vì chúng có thể làm lộ ra những điều mà mô hình biết nhưng không nói ra.
Để hiểu liệu NLAs có hữu ích cho việc kiểm toán hay không, chúng tôi đã tiến hành một thử nghiệm gọi là trò chơi kiểm toán mà chúng tôi cũng đã sử dụng trước đây để nghiên cứu các phương pháp kiểm toán. Trong thử nghiệm này, có một mô hình mục tiêu, một biến thể của Claude Haiku 3.5, được cố ý đào tạo để bị sai lệch, với một động cơ tiềm ẩn cụ thể thúc đẩy hàng tá hành vi kỳ lạ – cho sô cô la vào mọi công thức, yêu cầu tiền boa, phá vỡ các quy ước mã hóa, v.v. Mô hình mục tiêu này được giao cho một kiểm toán viên để điều tra các hành vi này. Kiểm toán viên thắng nếu họ khám phá ra động cơ cơ bản duy nhất đằng sau tất cả chúng.
Trong các thí nghiệm trước đây, chúng tôi nhận thấy rằng một số công cụ giải thích có thể giúp kiểm toán viên thắng trò chơi này. Tuy nhiên, các công cụ này hoạt động bằng cách giúp kiểm toán viên truy tìm hành vi bất thường của mục tiêu trở lại dữ liệu đào tạo bị sai lệch. Chúng tôi muốn biết liệu NLAs có thể giúp kiểm toán viên đọc trực tiếp động cơ sai lệch từ suy nghĩ của mô hình mục tiêu hay không, mà không cần phải khám phá dữ liệu đào tạo bị sai lệch trước. Điều này quan trọng vì trong thực tế, dữ liệu sai lệch có thể cực kỳ hiếm, hoặc có thể không có dữ liệu cụ thể nào chịu trách nhiệm cho sự sai lệch đó.
Chúng tôi nhận thấy rằng NLAs đã thành công trong thử nghiệm này. Một kiểm toán viên được trang bị NLAs đã khám phá thành công động cơ tiềm ẩn của mô hình mục tiêu từ 12% đến 15% thời gian, ngay cả khi không có quyền truy cập vào dữ liệu đào tạo đã cấy ghép nó. Nếu không có NLAs, kiểm toán viên thắng dưới 3% thời gian, ngay cả khi được cung cấp các công cụ giải thích khác.

Các kiểm toán viên với NLAs có thể khám phá nguyên nhân gốc rễ của sự sai lệch của mô hình mục tiêu, ngay cả khi không có quyền truy cập vào dữ liệu đào tạo. (NLAs và SAEs cho cả hai điều kiện đều được đào tạo chỉ bằng dữ liệu chung, không phải dữ liệu được sử dụng để đào tạo mô hình mục tiêu.)
Trò chơi kiểm toán này là một mô hình đồ chơi về sự sai lệch, vì vậy chúng tôi đọc những kết quả này một cách thận trọng. Nhưng chúng cho thấy NLAs đã thúc đẩy đáng kể khả năng của chúng tôi trong việc kiểm toán AI để tìm kiếm những động cơ tiềm ẩn. Trong thực tế, chúng tôi đã sử dụng NLAs trong các cuộc kiểm toán căn chỉnh trước khi triển khai của Claude Mythos Preview và Claude Opus 4.6. Chúng tôi rất vui mừng được tiếp tục sử dụng NLAs trong các cuộc điều tra của mình trong tương lai.
NLAs có một số hạn chế.
Hạn chế quan trọng nhất là các giải thích của NLA có thể sai. NLAs đôi khi đưa ra những tuyên bố về ngữ cảnh mà có thể kiểm chứng là sai – ví dụ, chúng đôi khi bịa ra các chi tiết không có trong bản ghi. Những ảo giác thực tế này rất dễ phát hiện bằng cách kiểm tra với văn bản gốc. Nhưng loại vấn đề tương tự này có thể mở rộng sang các tuyên bố về lập luận nội bộ của mô hình, điều này khó xác minh hơn. Trong thực tế, chúng tôi đọc các giải thích của NLA để tìm các chủ đề mà chúng làm nổi bật hơn là các tuyên bố đơn lẻ, và chúng tôi cố gắng xác nhận các phát hiện bằng các phương pháp độc lập trước khi hoàn toàn tin tưởng chúng.
