Anthropic nhấn mạnh rằng quyền truy cập của các tác nhân AI phải phát triển cùng với khả năng của chúng. Bằng cách sử dụng kỹ thuật "sandboxing", công ty tạo ra các môi trường biệt lập để thực thi mã lệnh, giới hạn phạm vi của bất kỳ hành động nào có khả năng gây hại và đảm bảo an toàn cho người dùng và hệ thống.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Twitter / X →

Anthropic đã bổ nhiệm Vas Narasimhan, CEO của Novartis, vào Hội đồng Quản trị thông qua Quỹ Tín thác Lợi ích Dài hạn. Động thái chiến lược này nhấn mạnh cam kết của Anthropic trong việc phát triển AI một cách an toàn và có trách nhiệm, đặc biệt là trong các lĩnh vực y tế và khoa học sự sống, đồng thời củng cố cấu trúc quản trị độc đáo của công ty.
04/05/2026
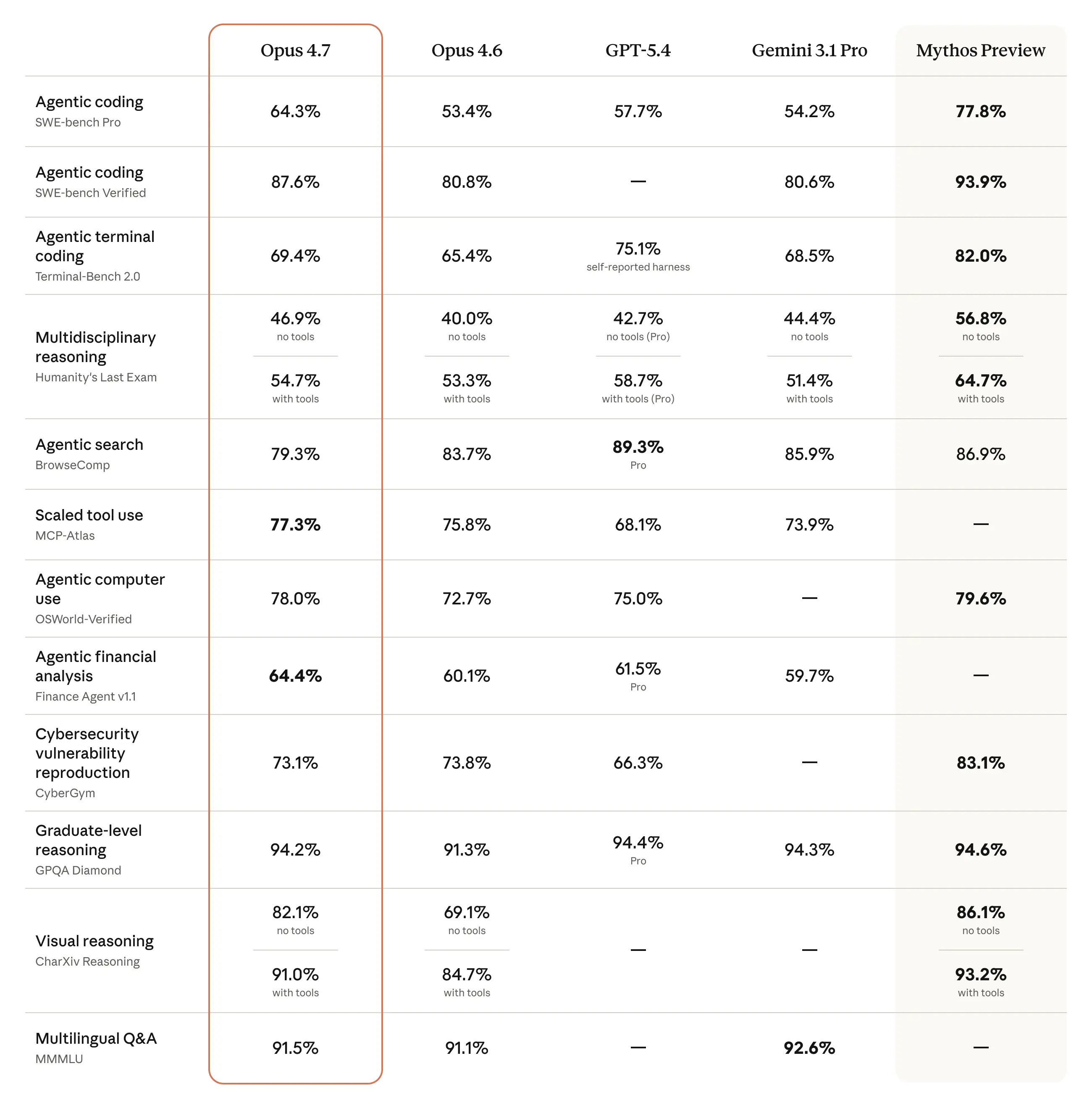
Anthropic vừa ra mắt Claude Opus 4.7, một phiên bản cải tiến đáng kể so với Opus 4.6, đặc biệt trong lĩnh vực kỹ thuật phần mềm và khả năng thị giác. Mô hình này có thể xử lý các tác vụ mã hóa phức tạp, chú ý đến hướng dẫn và tự kiểm tra đầu ra. Opus 4.7 cũng tích hợp các biện pháp bảo vệ an ninh mạng tiên tiến, đồng thời duy trì mức giá như phiên bản trước.
04/05/2026

Research powered by Tavily.
Anthropic và Amazon vừa công bố mở rộng hợp tác chiến lược, một bước đi quan trọng trong cuộc đua AI. Với cam kết hạ tầng trị giá 100 tỷ USD và khoản đầu tư lên tới 25 tỷ USD từ Amazon, Anthropic sẽ có thêm 5 gigawatt năng lực tính toán. Thỏa thuận này không chỉ củng cố vị thế của Claude trên nền tảng AWS mà còn hứa hẹn nâng cao hiệu suất và khả năng tiếp cận cho người dùng toàn cầu.
04/05/2026

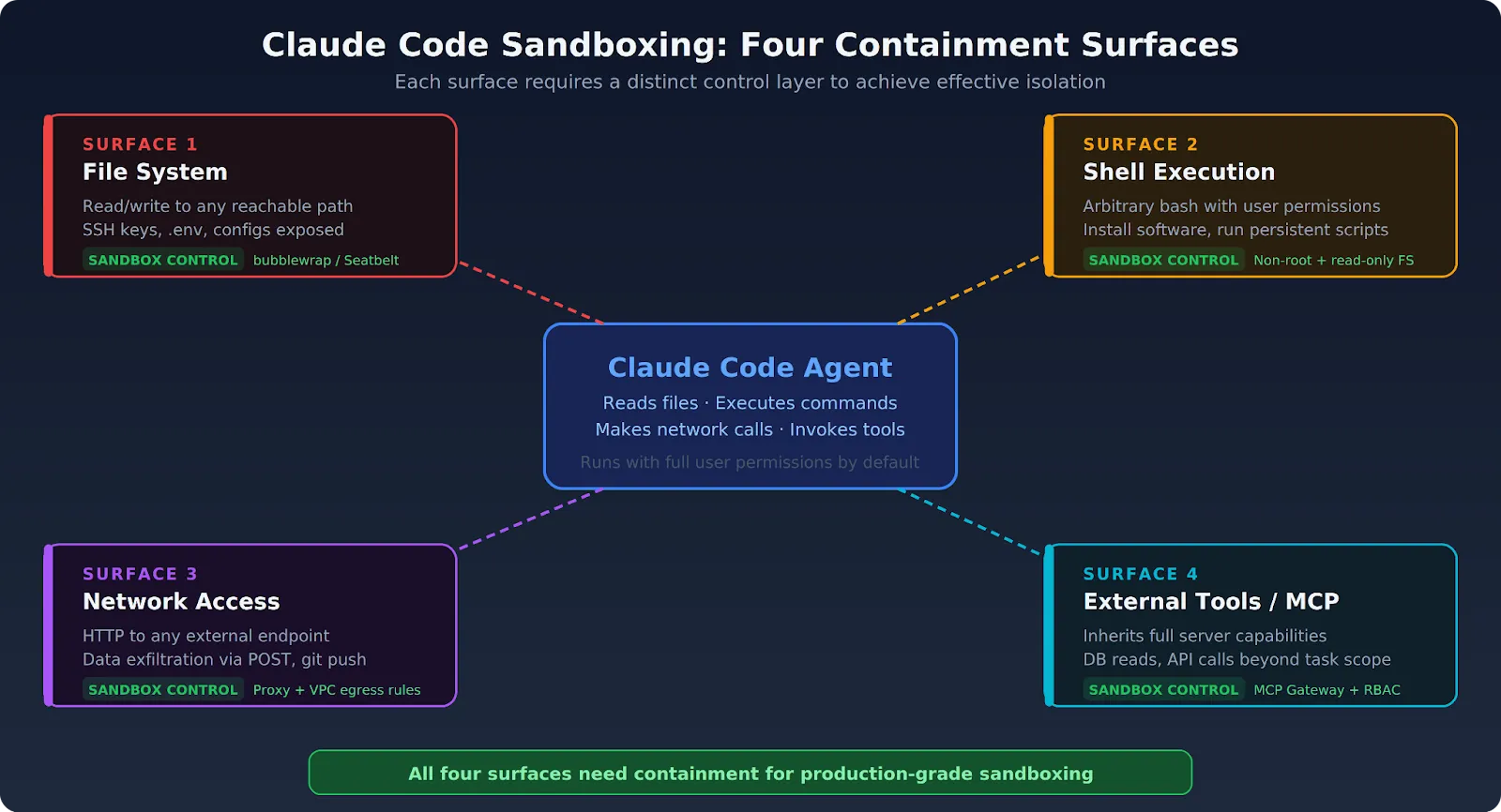
Sandboxing là một kỹ thuật bảo mật tạo ra một môi trường biệt lập, an toàn để chạy các chương trình hoặc mã lệnh không đáng tin cậy. Anthropic sử dụng nó để giới hạn các hành động của AI, ngăn chặn các tác vụ có khả năng gây hại. Cách tiếp cận này cho phép Claude thực thi mã lệnh một cách hữu ích mà không gây rủi ro cho hệ thống rộng lớn hơn.
Trong lĩnh vực AI, đặc biệt là với các mô hình có khả năng tự viết và thực thi mã như Claude, sandboxing không còn là một lựa chọn mà là một yêu cầu bắt buộc. Nó hoạt động như một "hộp cát" ảo, nơi AI có thể "chơi" với các công cụ và dữ liệu trong một không gian được kiểm soát chặt chẽ. Mọi hành động đều bị giám sát và giới hạn, đảm bảo rằng ngay cả khi AI cố gắng thực hiện một hành động nguy hiểm, nó cũng không thể ảnh hưởng đến bên ngoài hộp cát. Theo Anthropic (2026), việc cấp quyền cho AI cần được điều chỉnh linh hoạt theo năng lực ngày càng tăng của chúng, và sandboxing chính là cơ chế để thực thi triết lý đó.
Tầm quan trọng của việc quản lý rủi ro này còn được thể hiện qua khía cạnh chi phí. Theo TrueFoundry.com (2026), có tới 80% chi phí liên quan đến AI là vô hình trên hóa đơn, bao gồm cả các chi phí tiềm tàng từ sự cố bảo mật. Bằng cách đầu tư vào các biện pháp an toàn như sandboxing, các tổ chức có thể phòng ngừa những tổn thất tài chính và uy tín không lường trước được. Đây là một phần trong cam kết của Anthropic về việc xây dựng các hệ thống AI đáng tin cậy, có thể diễn giải và có thể điều khiển được.
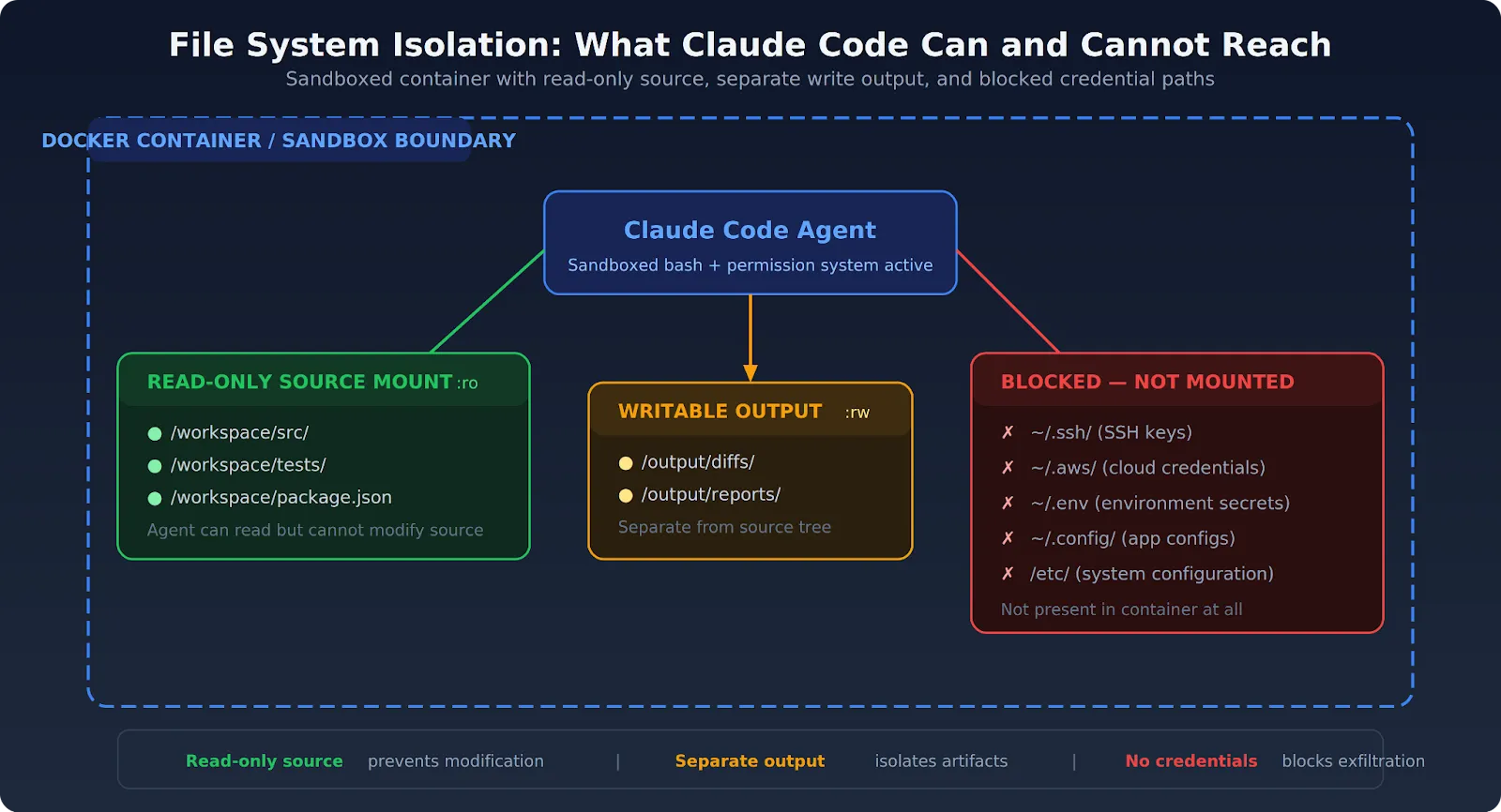
Anthropic triển khai sandboxing bằng cách tạo các môi trường thực thi mã lệnh tạm thời và bị cô lập cho Claude, đặc biệt là trong tính năng Claude Code. Môi trường này có các giới hạn nghiêm ngặt về truy cập mạng, hệ thống tệp và tài nguyên hệ thống. Các tham số như autoAllowBashIfSandboxed giúp tự động hóa việc cấp phép trong môi trường an toàn, tăng hiệu quả mà không giảm bảo mật.
Về cơ bản, hệ thống sandboxing của Anthropic được thiết kế để trả lời hai câu hỏi cốt lõi mỗi khi Claude cần thực thi một hành động: "should this tool run?" (công cụ này có nên chạy không?) và "if it runs, what can it actually touch?" (nếu nó chạy, nó thực sự có thể chạm vào những gì?). Câu trả lời cho những câu hỏi này được xác định bởi một tập hợp các quy tắc và cấu hình linh hoạt. Ví dụ, quản trị viên có thể thiết lập các tham số như allowUnsandboxedCommands để cho phép hoặc cấm các lệnh chạy bên ngoài sandbox, mang lại sự kiểm soát chi tiết. Thử nghiệm nội bộ cho thấy phương pháp này giúp giảm 84% số lần yêu cầu cấp phép, theo một phân tích của TrueFoundry.com (2026). Điều này cho thấy công nghệ này vừa hiệu quả về mặt bảo mật, vừa tối ưu cho trải nghiệm người dùng.
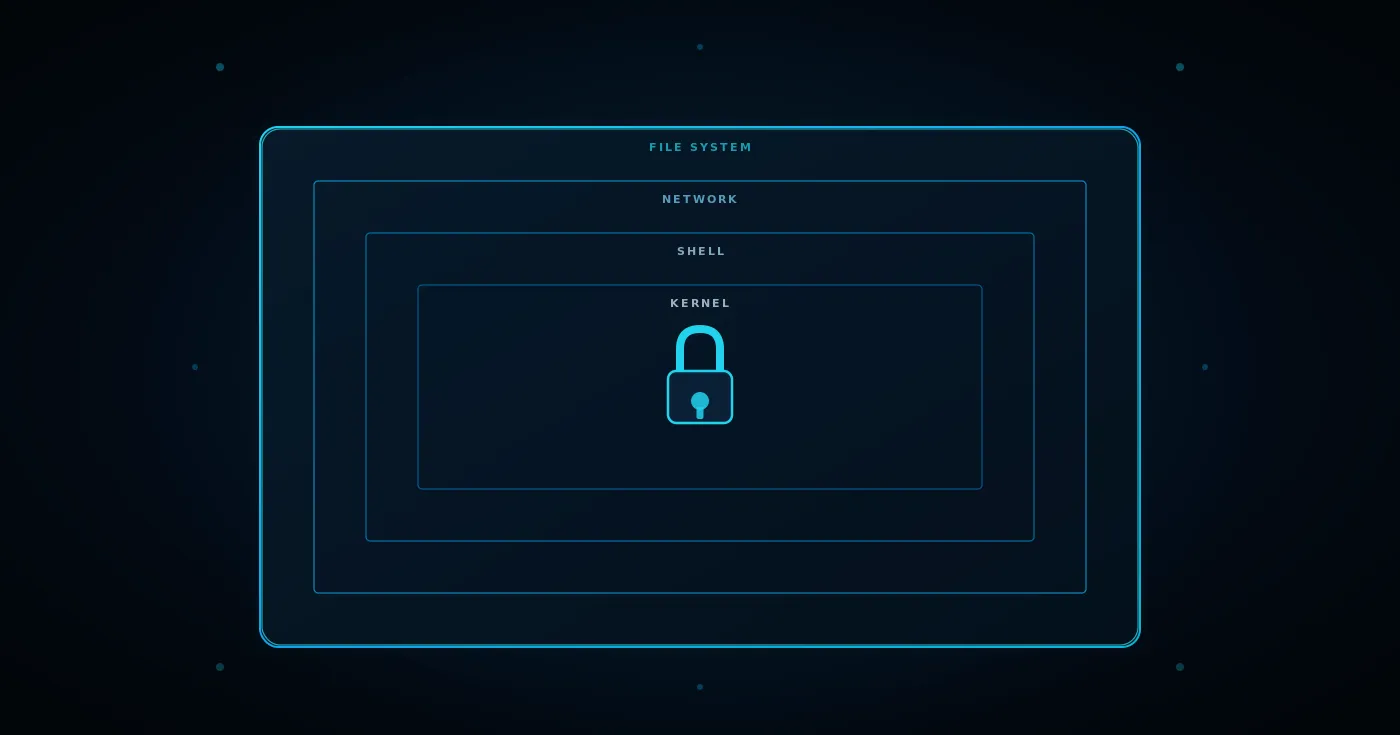
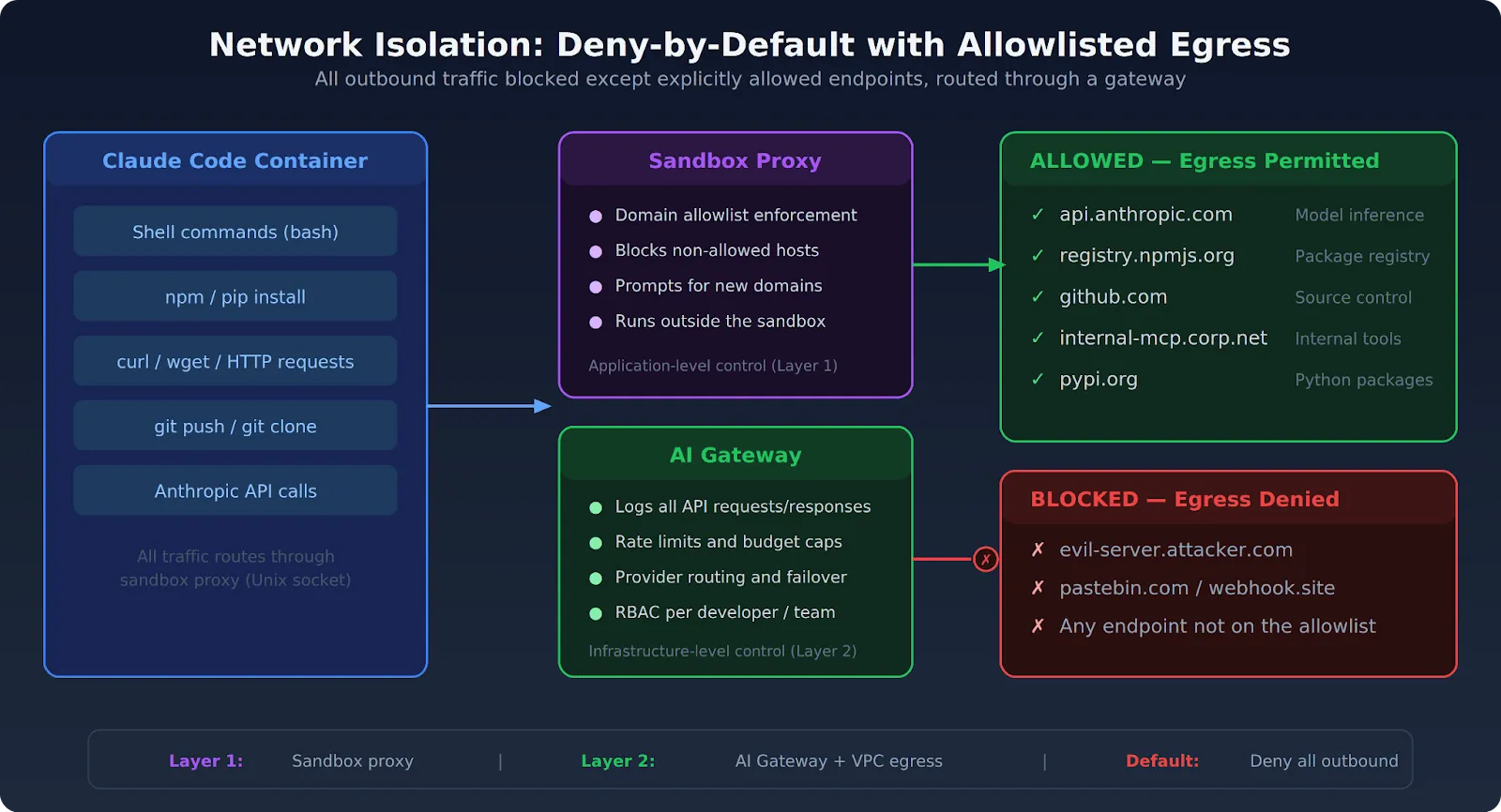
Hệ thống này cũng bao gồm các biện pháp kiểm soát truy cập mạng và hệ thống tệp. Ví dụ, Claude chỉ có thể truy cập vào một thư mục tạm thời được tạo riêng cho mỗi phiên làm việc và sẽ bị xóa ngay sau khi hoàn tất. Mọi nỗ lực truy cập ra bên ngoài thư mục này đều bị chặn. Tương tự, các kết nối mạng ra bên ngoài cũng bị giới hạn nghiêm ngặt, chỉ cho phép các kết nối đến những địa chỉ đã được phê duyệt trước, ngăn chặn nguy cơ rò rỉ dữ liệu hoặc tấn công vào các hệ thống khác.
Không có biện pháp bảo mật nào là tuyệt đối, và sandboxing cũng không ngoại lệ. Gần đây, các nhà nghiên cứu đã phát hiện và Anthropic đã âm thầm vá một lỗ hổng cho phép vượt qua sandbox của Claude Code. Điều này cho thấy sự cần thiết của việc kiểm tra, giám sát và cập nhật liên tục để đối phó với các mối đe dọa mới nổi.
Theo SecurityWeek (2026), nhà nghiên cứu bảo mật Aonan Guan đã phát hiện hai lỗ hổng cho phép vượt qua sandbox mạng của Claude Code. Lỗ hổng nghiêm trọng hơn liên quan đến việc sandbox diễn giải sai một cài đặt chặn toàn bộ lưu lượng truy cập ra ngoài thành "cho phép tất cả". Nếu bị khai thác, kẻ tấn công có thể kết hợp lỗ hổng này với kỹ thuật tấn công prompt injection để trích xuất dữ liệu nhạy cảm. Điều này là một lời nhắc nhở rằng ngay cả những hệ thống được thiết kế cẩn thận nhất cũng có thể có những điểm yếu không lường trước được.

Theo nhà nghiên cứu, lỗ hổng này đã tồn tại trong Claude Code từ tháng 10 năm 2025, khi sandbox được cung cấp rộng rãi cho người dùng. Việc Anthropic vá lỗi một cách "âm thầm" mà không công bố rộng rãi hay cấp mã định danh CVE (Common Vulnerabilities and Exposures) đã gây ra một số tranh cãi. Tuy nhiên, sự việc này cũng nhấn mạnh tầm quan trọng của cộng đồng nghiên cứu bảo mật trong việc tìm kiếm và báo cáo các lỗ hổng, góp phần làm cho các hệ thống AI trở nên an toàn hơn. Nó cho thấy an toàn AI là một quá trình liên tục, một cuộc rượt đuổi không ngừng giữa việc xây dựng phòng tuyến và việc tìm cách phá vỡ chúng.

Khi các mô hình AI trở nên mạnh mẽ hơn, khả năng gây hại của chúng nếu bị lạm dụng cũng tăng theo. Việc cấp quyền truy cập không tương xứng có thể dẫn đến hậu quả khó lường, từ rò rỉ dữ liệu đến các hành động phá hoại. Do đó, Anthropic chủ trương một chính sách "leo thang có trách nhiệm", điều chỉnh quyền hạn của AI song song với sự phát triển năng lực của nó.
Trong một tuyên bố chính thức, Anthropic đã nêu rõ: "The access and permissions we grant agents should evolve with their capabilities." (Quyền truy cập và cấp phép chúng ta cấp cho các tác nhân nên phát triển cùng với khả năng của chúng). Theo x.com (2026), đây là nguyên tắc cốt lõi định hướng cho việc phát triển sản phẩm của họ. Một mô hình AI đơn giản chỉ dùng để tóm tắt văn bản không cần quyền truy cập hệ thống tệp. Nhưng một tác nhân AI có khả năng quản lý dự án phức tạp có thể cần quyền truy cập lịch, email và các công cụ khác. Việc phân cấp quyền hạn này giúp giảm thiểu bề mặt tấn công và hạn chế thiệt hại khi có sự cố xảy ra.
Thách thức này càng trở nên cấp thiết trong bối cảnh các công cụ giám sát AI vẫn còn non trẻ. Một phân tích của TrueFoundry.com (2026) cho thấy chỉ khoảng 1% các nền tảng giám sát LLM hiện có được coi là hàng đầu. Khi khả năng giám sát còn hạn chế, việc giới hạn quyền hạn của AI ngay từ đầu thông qua các cơ chế như sandboxing trở thành tuyến phòng thủ quan trọng nhất. Đây là cách tiếp cận phòng ngừa, thay vì chỉ phản ứng khi sự cố đã xảy ra.
Doanh nghiệp nên áp dụng nguyên tắc "ít đặc quyền nhất" (principle of least privilege) khi triển khai AI, chỉ cấp những quyền hạn thực sự cần thiết cho một tác vụ cụ thể. Việc sử dụng sandboxing, giám sát liên tục và có kế hoạch ứng phó sự cố là rất quan trọng. Cách tiếp cận này giúp khai thác sức mạnh của AI trong khi vẫn kiểm soát được rủi ro.
Thay vì cấp cho AI quyền truy cập rộng rãi vào toàn bộ hệ thống, các doanh nghiệp nên xem xét việc tạo ra các môi trường biệt lập cho từng ứng dụng AI. Điều này không chỉ giới hạn tác động của các sự cố bảo mật mà còn giúp việc gỡ lỗi và quản lý trở nên dễ dàng hơn. Valence Security (2026) cũng nhấn mạnh rằng việc quản trị sử dụng AI trong doanh nghiệp là một bài toán phức tạp, đòi hỏi sự kết hợp giữa chính sách rõ ràng và các công cụ kỹ thuật để thực thi chúng một cách hiệu quả.
Hơn nữa, việc bỏ qua các biện pháp an toàn có thể dẫn đến chi phí khổng lồ. Như một nghiên cứu năm 2026 của TrueFoundry.com đã chỉ ra, 80% chi phí AI là "vô hình" và thường liên quan đến rủi ro, quản trị và các sự cố không lường trước. Đầu tư vào các giải pháp an toàn như sandboxing và các nền tảng giám sát không phải là chi phí, mà là một khoản đầu tư để bảo vệ tài sản số, uy tín thương hiệu và đảm bảo sự phát triển bền vững trong kỷ nguyên AI. Cách tiếp cận của Anthropic cung cấp một mô hình tham khảo giá trị cho bất kỳ tổ chức nào muốn khai thác AI một cách có trách nhiệm.