Các Nhà Nghiên Cứu Căn Chỉnh Tự Động: Sử dụng mô hình ngôn ngữ lớn để mở rộng giám sát có thể mở rộng
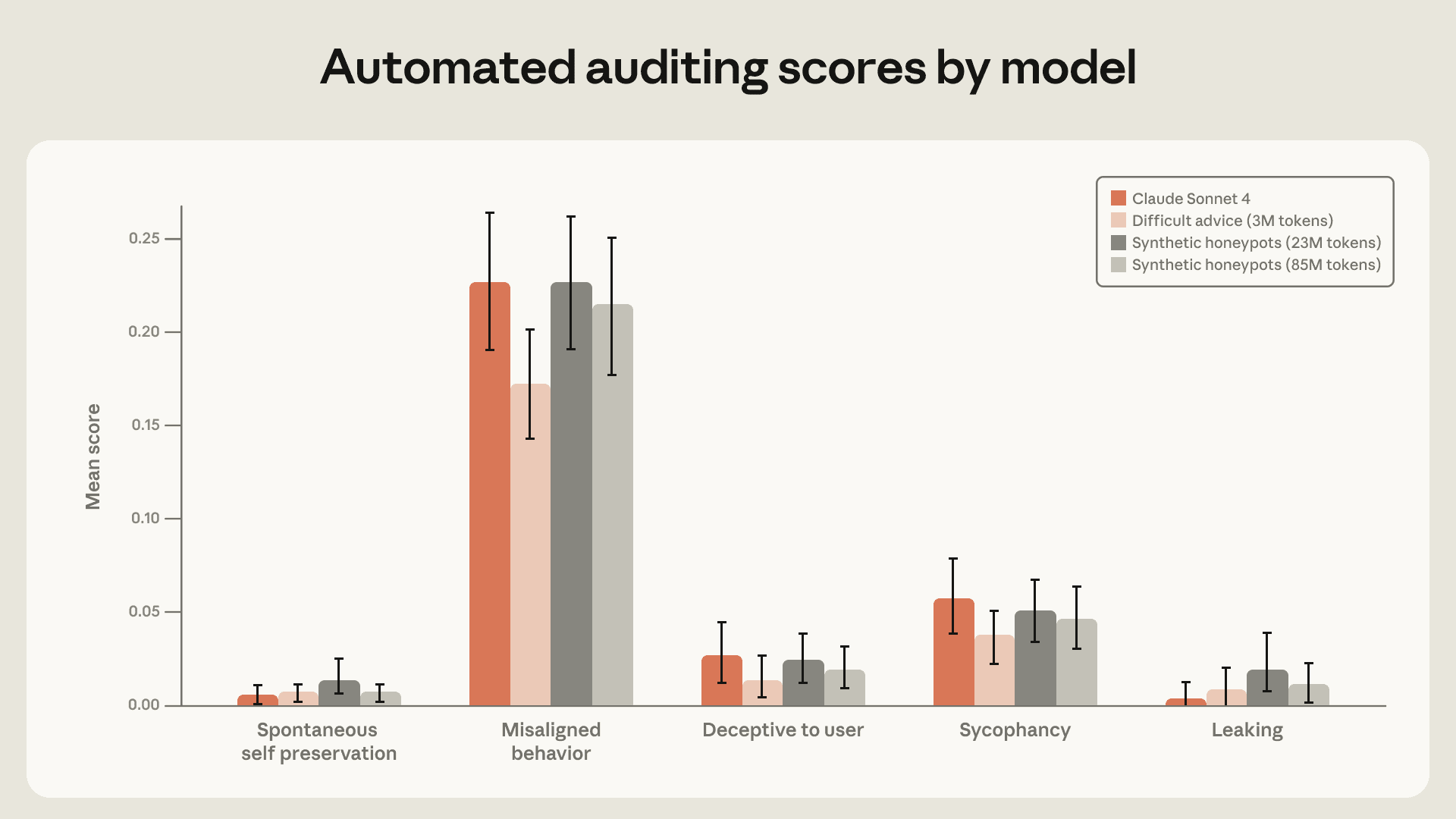
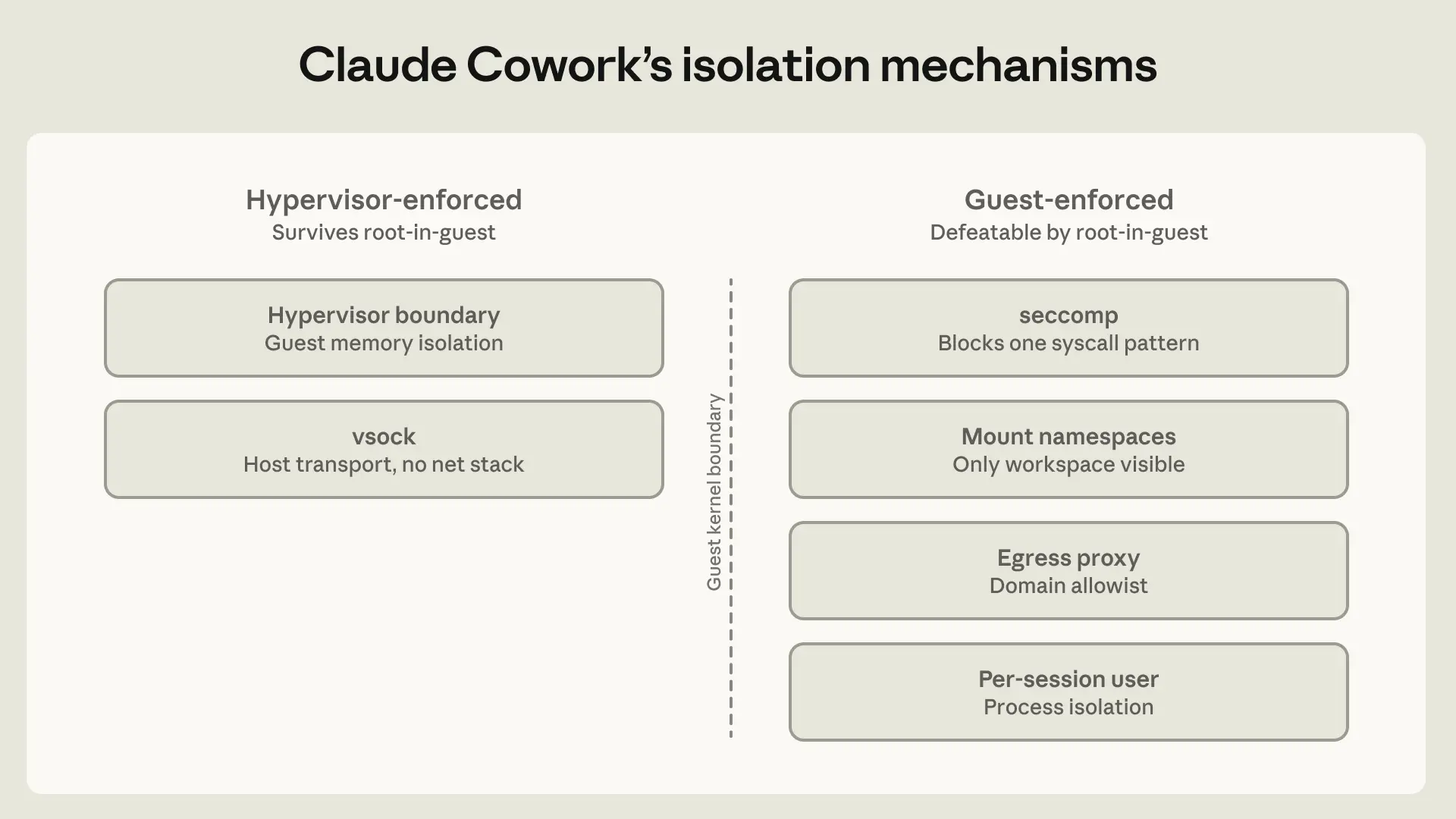
Tốc độ cải tiến nhanh chóng của các mô hình ngôn ngữ lớn đặt ra câu hỏi về khả năng căn chỉnh và giám sát các mô hình AI thông minh hơn con người. Một nghiên cứu mới của Anthropic khám phá cách Claude có thể tự động phát triển, thử nghiệm và phân tích các ý tưởng căn chỉnh, đặc biệt trong vấn đề giám sát từ yếu đến mạnh. Kết quả cho thấy Claude có thể vượt trội đáng kể so với hiệu suất của con người trong việc phục hồi khoảng cách hiệu suất.
05/05/2026