Sự kiện Jan Leike, một trong những nhà nghiên cứu an toàn AI hàng đầu, gia nhập Anthropic đang tạo ra làn sóng trong ngành. Dự án mới của anh không chỉ tập trung vào 'căn chỉnh' mà còn hướng tới một cách tiếp cận toàn diện hơn để đảm bảo Trí tuệ tổng quát nhân tạo (AGI) phát triển an toàn và có lợi cho nhân loại. Điều này đánh dấu một chương mới đầy hứa hẹn cho Anthropic.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Twitter / X →
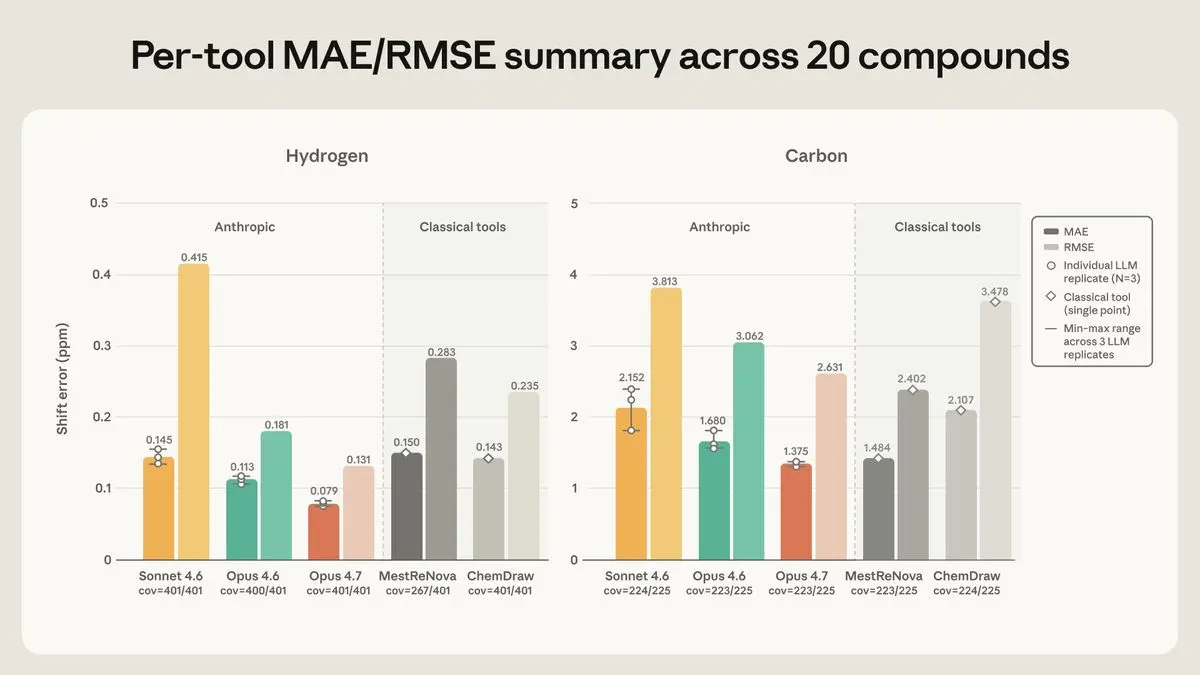
Anthropic đang phát triển Claude để trở thành một công cụ mạnh mẽ cho ngành hóa học. Bằng cách tận dụng khả năng đa phương thức và suy luận tường minh, Claude có thể phân tích dữ liệu phức tạp như phổ NMR, vượt qua các phần mềm chuyên dụng và hứa hẹn đẩy nhanh tốc độ khám phá khoa học trong phòng thí nghiệm.
06/06/2026
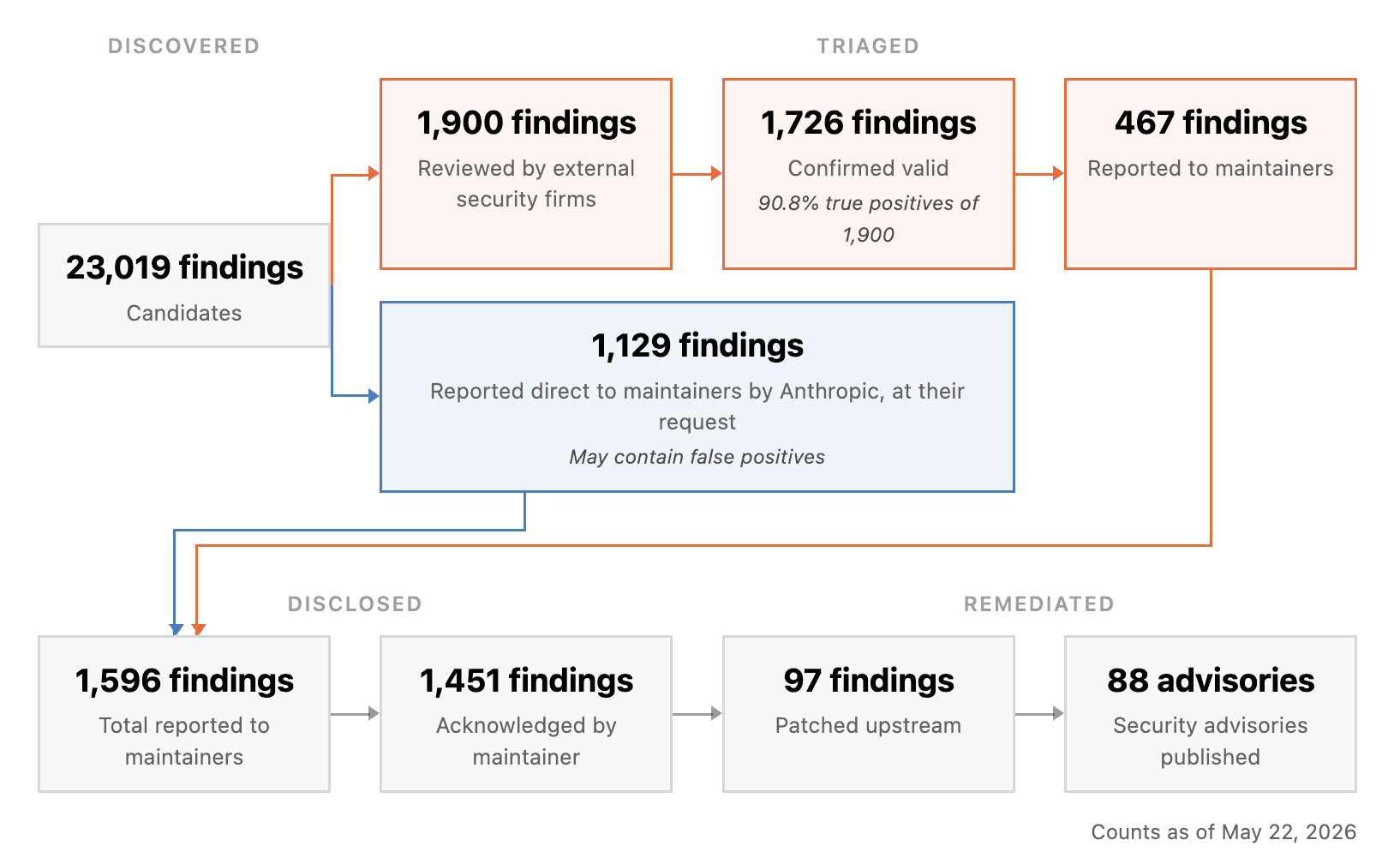
Anthropic đang mở rộng đáng kể Dự án Glasswing, một nỗ lực hợp tác nhằm bảo vệ các phần mềm quan trọng nhất thế giới bằng AI. Với việc bổ sung 150 tổ chức từ hơn 15 quốc gia, dự án tập trung vào các lĩnh vực hạ tầng trọng yếu. Sáng kiến này sử dụng mô hình Claude Mythos Preview để chủ động phát hiện lỗ hổng, chuẩn bị cho một kỷ nguyên mới của an ninh mạng.
04/06/2026

Research powered by Tavily.
Anthropic đang kêu gọi cộng đồng người dùng Claude chia sẻ kinh nghiệm về mức độ 'suy nghĩ' của AI. Nhà nghiên cứu Sholto Douglas muốn biết liệu Claude có đang cân bằng tốt giữa việc phân tích sâu và phản hồi nhanh hay không. Phản hồi của bạn sẽ giúp tối ưu hóa hiệu suất, chi phí và trí thông minh của các thế hệ Claude tiếp theo.
28/05/2026
Jan Leike là một trong những nhà nghiên cứu hàng đầu thế giới về an toàn và căn chỉnh AI. Việc ông gia nhập Anthropic sau khi rời OpenAI là một sự kiện quan trọng, khẳng định vị thế của Anthropic như một trung tâm hàng đầu về nghiên cứu AI có trách nhiệm. Động thái này không chỉ là một sự dịch chuyển nhân sự cấp cao mà còn là tín hiệu về sự hội tụ của những bộ óc ưu tú nhất hướng tới mục tiêu chung là AGI an toàn.
Trước khi đến Anthropic, Leike đã có một sự nghiệp lẫy lừng tại các tổ chức AI tiên phong nhất. Theo Wikipedia (2026), ông đã làm việc tại DeepMind và sau đó là OpenAI, nơi ông đồng lãnh đạo nhóm Superalignment. Nhiệm vụ của nhóm này là giải quyết các thách thức kỹ thuật trong việc kiểm soát các hệ thống AI thông minh hơn con người. Tuy nhiên, theo CNBC (2024), ông đã rời OpenAI do những bất đồng về văn hóa và ưu tiên an toàn. Việc ông chọn Anthropic làm điểm đến tiếp theo cho thấy sự tương đồng sâu sắc về tầm nhìn và triết lý. Anthropic, được thành lập bởi các cựu thành viên của OpenAI, luôn đặt an toàn lên hàng đầu trong sứ mệnh của mình. Trong khi hơn 90% mọi người vẫn đang cố gắng nắm bắt các thuật ngữ AI cơ bản, theo Medium (2026), những người như Leike đang ở tuyến đầu, định hình tương lai của công nghệ này.

Dự án nghiên cứu mới của Jan Leike tại Anthropic tập trung vào việc xây dựng AGI an toàn theo một cách tiếp cận toàn diện hơn. Thay vì chỉ tập trung vào "căn chỉnh" (alignment), dự án sẽ khám phá nhiều khía cạnh cần thiết khác để đảm bảo AGI hoạt động tốt. Chi tiết cụ thể vẫn chưa được công bố, nhưng nó hứa hẹn một hướng đi đột phá vượt ra ngoài các khuôn khổ hiện có.
Trong một thông báo ngắn gọn nhưng đầy ý nghĩa, Jan Leike đã chia sẻ trên X. Theo X (2026), ông viết: "Some personal news: I am starting a new research project at Anthropic. Very excited about this! Many things are needed to make AGI go well, and alignment is only one of them. More on this soon…" (tạm dịch: "Một vài tin tức cá nhân: Tôi đang bắt đầu một dự án nghiên cứu mới tại Anthropic. Rất hào hứng về điều này! Cần nhiều yếu tố để AGI phát triển tốt, và căn chỉnh chỉ là một trong số đó. Sẽ có thêm thông tin sớm..."). Tuyên bố này cho thấy một sự thay đổi trong tư duy, nhìn nhận vấn đề an toàn AGI như một bài toán đa chiều. Theo CryptoBriefing (2026), việc Leike dẫn dắt một nhóm mới tại Anthropic là sự củng cố cho cam kết của công ty đối với khoa học an toàn. Những dự án như thế này đòi hỏi nguồn lực khổng lồ, và Anthropic đã chứng tỏ sự sẵn sàng đầu tư. Chẳng hạn, theo Medium (2026), công ty đã cam kết tới 100 triệu đô la tín dụng sử dụng để hỗ trợ các nỗ lực nghiên cứu và an ninh mạng trong hệ sinh thái.
Phát triển AGI thành công đòi hỏi một chiến lược an toàn đa tầng, bởi "căn chỉnh" – dạy AI hành động theo giá trị của con người – chỉ là một mảnh ghép. Các vấn đề khác như an ninh mạng, khả năng diễn giải (interpretability), khả năng kiểm soát (controllability), và ngăn chặn lạm dụng bởi các tác nhân xấu cũng cực kỳ quan trọng. Một AGI được căn chỉnh hoàn hảo nhưng dễ bị hack vẫn là một thảm họa tiềm tàng.
Quan điểm của Leike phản ánh một sự thật ngày càng được công nhận trong ngành: an toàn AI là một lĩnh vực phức hợp. Theo Dario Amodei, CEO của Anthropic, trong một cuộc phỏng vấn với Lex Fridman (2024), việc xây dựng các hệ thống AI an toàn giống như xây dựng một nhà máy điện hạt nhân – bạn cần nhiều lớp bảo vệ, từ thiết kế lò phản ứng đến quy trình vận hành và kế hoạch ứng phó sự cố. Một ví dụ cụ thể là lĩnh vực an ninh mạng. Theo Medium (2026), nghiên cứu của Anthropic cho thấy các mô hình AI có thể tự động tìm ra các lỗ hổng bảo mật, với hơn 99% lỗ hổng được phát hiện vẫn chưa được vá. Điều này nhấn mạnh tầm quan trọng của việc xây dựng các hệ thống AI không chỉ "tốt" mà còn "mạnh mẽ" và "bảo mật". Dự án của Leike có thể sẽ khám phá cách tích hợp các biện pháp bảo vệ này vào chính lõi của AGI.
Việc thu hút một tài năng hàng đầu như Jan Leike củng cố mạnh mẽ vị thế của Anthropic như một nhà lãnh đạo không thể tranh cãi trong lĩnh vực nghiên cứu AI an toàn. Động thái này không chỉ nâng cao uy tín của công ty mà còn tạo ra một "lực hút" đối với các nhà nghiên cứu tài năng khác. Nó gửi đi một thông điệp rõ ràng: Anthropic là nơi dành cho những ai muốn giải quyết các vấn đề cốt lõi và khó khăn nhất của AGI.
Trong bối cảnh cạnh tranh khốc liệt, việc có được những bộ óc như Leike là một lợi thế chiến lược. Theo CNBC (2024), sự chuyển dịch nhân tài từ OpenAI sang Anthropic cho thấy cuộc đua AGI không chỉ là về sức mạnh tính toán mà còn về triết lý và văn hóa an toàn. Anthropic đã tạo sự khác biệt bằng các phương pháp độc đáo như Hiến pháp AI (Constitutional AI), một cách tiếp cận để định hình hành vi của mô hình mà không cần giám sát liên tục của con người, theo Anthropic (2024). Bằng cách tập hợp các chuyên gia hàng đầu và theo đuổi một chương trình nghị sự nghiên cứu táo bạo, Anthropic không chỉ tham gia cuộc đua mà còn đang nỗ lực định hình các quy tắc của nó. Việc hiểu rõ các khái niệm này giúp Anthropic vượt lên trên 90% các công ty khác, theo một phân tích của Medium (2026).
Từ hướng nghiên cứu mới do Jan Leike dẫn dắt, chúng ta có thể kỳ vọng những đột phá trong các lĩnh vực an toàn AI tiên tiến. Điều này có thể bao gồm các phương pháp giám sát có thể mở rộng (scalable oversight), kỹ thuật diễn giải hành vi của AI (interpretability), và các giao thức bảo mật mạnh mẽ để chống lại việc lạm dụng các hệ thống AI có năng lực cao. Kết quả nghiên cứu có thể sẽ định hình các tiêu chuẩn an toàn cho toàn ngành.
Những tiến bộ này sẽ không chỉ tồn tại trên lý thuyết. Chúng có khả năng được tích hợp trực tiếp vào các thế hệ tiếp theo của gia đình mô hình Claude, làm cho chúng trở nên mạnh mẽ, hữu ích và an toàn hơn. Theo Báo cáo Xu hướng Lập trình Tác tử 2026 của Anthropic (2026), tương lai của AI nằm ở các hệ thống tác tử (agentic systems) có khả năng thực hiện các nhiệm vụ phức tạp một cách tự chủ. Nghiên cứu của Leike sẽ rất quan trọng để đảm bảo các tác tử này hoạt động một cách an toàn và đáng tin cậy. Hơn nữa, các nhà phát triển sử dụng API của Claude, như được hướng dẫn trong tài liệu của AG2 (2026), cũng sẽ được hưởng lợi gián tiếp khi nền tảng cơ bản trở nên vững chắc hơn. Cam kết trị giá 100 triệu đô la mà Anthropic đưa ra, theo Medium (2026), cho thấy họ sẵn sàng đầu tư mạnh mẽ để biến những tầm nhìn nghiên cứu này thành hiện thực, mang lại lợi ích cho toàn bộ hệ sinh thái AI.